User Guide
Overview
Below is a high-level overview of LeanDojo. A Lean project is a Git repo
consisting of multiple source files (*.lean). Each file has
multiple theorems (and their proofs). Given a Lean repo, LeanDojo first traces it.
The results are traced repo, files, and theorems with rich syntactic/semantic information not readily available in source code but useful
for downstream tasks, including but not limited to tactic states, tactics, and premises in tactics.
Once we have traced repo/files/theorems, constructing datasets is simply a matter of post-processing.
Once a theorem is traced, LeanDojo enables us to interact with it by replacing the original, human-written proof with
a special repl tactic. Unlike regular tactics transforming the goal in predefined ways,
the repl tactic reads tactics from an external prover, executes them in Lean, and reports the results back.
We name the resulting artifact Dojo (道場, the Japanese word for a gym for practicing martial arts).
Any external prover (potentially based on machine learning) can interact with Dojo to practice the art of theorem proving.
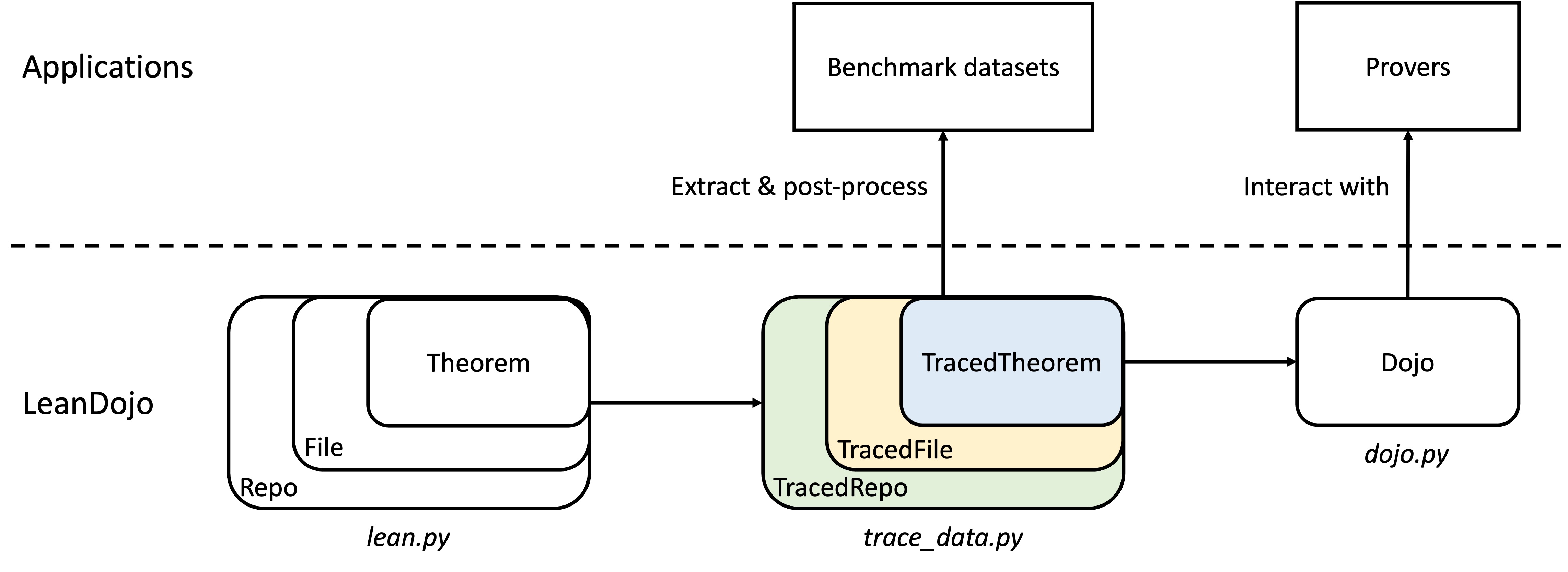
Next, we explain each concept in more detail.
Lean Repos and Files
We use lean-liquid in Lean 3 as an example
of Lean repos. It is a formalization of Peter Scholze’s Liquid Tensor Experiments.
Every Lean 3 repo has a config file leanpkg.toml at its root. [1] For example,
[package]
name = "lean-liquid"
version = "0.1"
lean_version = "leanprover-community/lean:3.48.0"
path = "src"
[dependencies]
mathlib = {git = "https://github.com/leanprover-community/mathlib", rev = "5947fb69cc1fdfebaba1e1b1f0a04f26f0f612bf"}
In the config file, lean_version specifies the version of Lean this repo requires. path specifies
the directory for Lean source files. And [dependencies] tells us
the repo depends on a specific commit of mathlib.
The repo can be compiled by running leanpkg build, which performs two steps under the hood:
Run
lean configureto pull all dependencies (only mathlib here) into the_target/deps/directory.Run
lean --make srcto compile the Lean source files (srcis configurable inleanpkg.toml). Think of it as Lean’s analogy of GNU Make, which is smart enough to figure out dependencies.
For each *.lean file, the compilation process checks all proofs in it
and produces a *.olean file (analogous to compiling *.cpp to *.o).
You may find more information about the toolchain of Lean 3 here
and related LeanDojo implementation in lean_dojo.data_extraction.lean.
Lean 4 uses a different build system ([lake](https://github.com/leanprover/lake)) with different configuration files and directory structures. However, the high-level idea is the same.
Theorems and Proofs
Theorems can be proved in Lean in multiple styles (term-style, tactic-style, mixed-style, etc.). We focus on tactic-style proofs. A proof is a sequence of tactics. Think of a tactic as a proof step. Each tactic transforms current goals into (hopefully simpler) sub-goals. The proof is complete when all remaining goals become trivial. Below is an example of interacting with a proof assistant to prove the theorem about summing \(n\) positive integers.
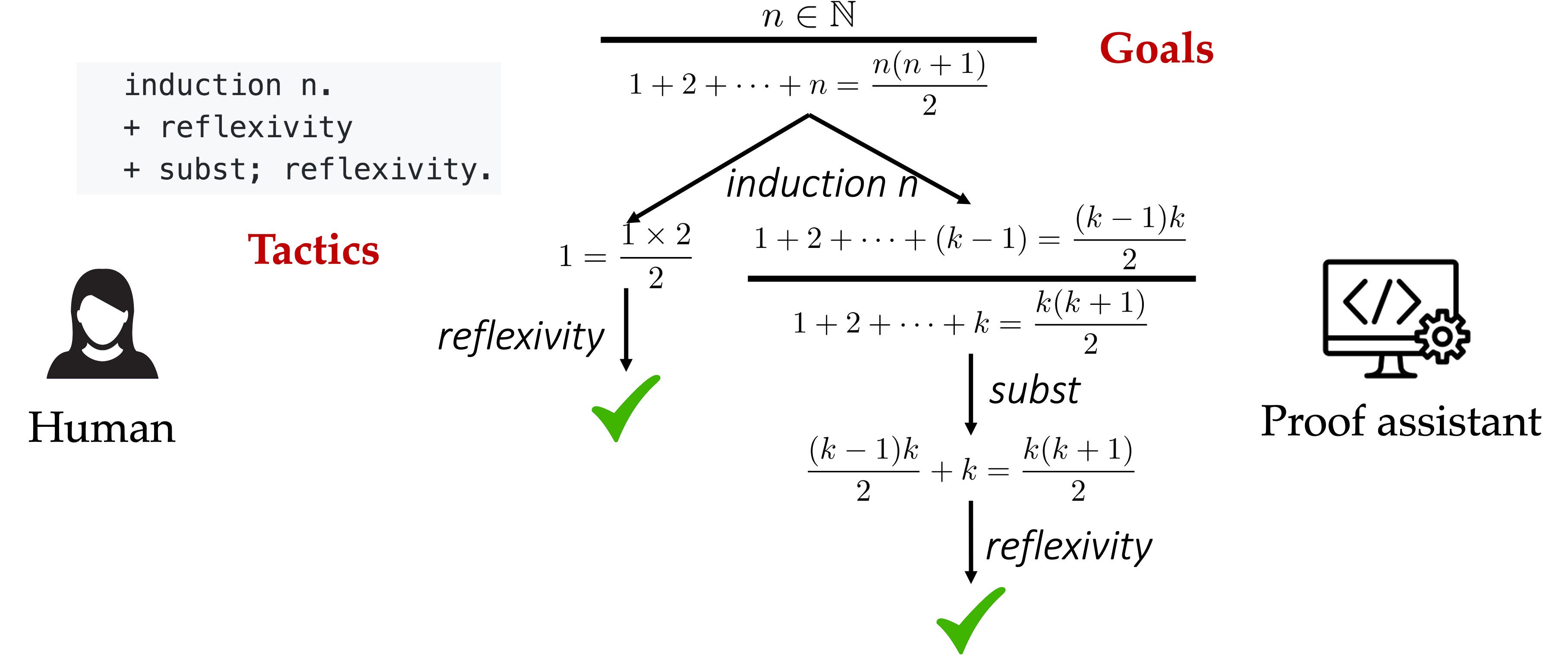
Initially, we know \(n \in \mathbb{N}\) and want to prove \(1 + 2 + \dots + n = \frac{n (n + 1)}{2}\).
We enter the tactic induction n to reason by induction on the integer \(n\), which leads to two sub-goals,
one corresponding to \(n = 0\) and the other corresponding to \(n \gt 0\). Then we enter the tactic
reflexivity to prove the trivial case (\(n = 0\)). Finally, we enter the tactic subst; reflexivity
to finish the proof. This process generates a proof tree whose nodes are tactic states (states for short) and whose edges
are tactics. Each state has a goal (e.g., \(1 + 2 + \dots + n = \frac{n (n + 1)}{2}\)) and a local context consisting of
hypotheses local to the goal (e.g., \(n \in \mathbb{N}\)).
Theorems/proofs do not exist in isolation. When proving a theorem, we almost inevitably rely on existing theorems and definitions. Consider a simple example we’ve seen in Getting Started:
open nat (add_assoc add_comm)
theorem hello_world (a b c : ℕ) : a + b + c = a + c + b :=
begin
rw [add_assoc, add_comm b, ←add_assoc]
end
The tactic rw [add_assoc, add_comm b, ←add_assoc] uses the premise add_assoc,
which is an existing theorem stating that the addition between natural numbers is associative
(Similarly, add_comm is about commutativity). Premise selection, i.e. generating the
premises add_assoc and add_comm, is a major challenge in theorem proving (for
both humans and machines). This is because the space of potentially useful premises is huge.
In principle, it includes all existing math when we attempt to prove a new math theorem. In practice,
there can be hundreds of thousands of potential premises, which cannot fit into the input window of
any Transformer-based large language model. Therefore, it is difficult for these models to perform
premise selection effectively when generating tactics.
We have presented a vastly simplified view of theorems and proofs in Lean. For more detail, Theorem Proving in Lean (3, 4)
is the definitive source. You may also refer to Sec. 3 of the LeanDojo paper.
In LeanDojo, theorems are implemented by the lean_dojo.data_extraction.lean.Theorem class.
Traced Repos
Conceptually, a traced repo is simply a collection of traced files. These files form a directed acyclic graph (DAG) by importing each other. They include not only files from the target repo but also dependencies that are actually used by the target repo. Taking lean-liquid in Lean 3 as an example, it depends on mathlib and Lean’s standard library. The corresponding traced repo includes all traced files from lean-liquid, as well as some files from mathlib and Lean’s standard library that are actually used by lean-liquid. After tracing finishes, these files are stored on the disk in the following directories:
lean-liquid
├─src
└─_target
└─deps
├─lean
│ └─library
└─ mathlib
We call lean-liquid the root directory of the traced repo.
Lean’s standard library is in lean-liquid/_target/deps/lean/library.
Source files of lean-liquid itself are in lean-liquid/src.
Mathlib and other dependencies (if any) are in lean-liquid/_target/deps.
In Lean 4, dependencies are stored in lake-packages instead of _target/deps.
In LeanDojo, traced repos are implemented by the lean_dojo.data_extraction.traced_data.TracedRepo class.
Traced Files
Tracing a *.lean file generates the following files:
*.olean: Lean’s compiled object file. We’re not concerned with them.*.dep_paths: Paths of dependencies imported by the*.leanfile. We generate them usinglean --deps(Lean 3) or ExtractData.lean (Lean 4).*.ast.json: AST of the*.leanfile annotated with semantic information such as tactic states and name resolutions. We generate them usinglean --ast --tsast --tspp(Lean 3) or ExtractData.lean (Lean 4).*.trace.xml: Syntactic and semantic information extracted from Lean. They are generated by post-processing*.dep_pathsand*.ast.jsonfiles to organize the information in a nice way.
In LeanDojo, tracing is done by running build_lean3_repo.py
with our modified Lean 3 or
build_lean4_repo.py with
ExtractData.lean
Traced files are implemented by the lean_dojo.data_extraction.traced_data.TracedFile class.
Traced Theorems and Tactics
Traced theorems and tactics provide easy access to various information, such as the human-written
proof of a theorem, the number of tactics in a theorem, the premises used in a theorem/tactic,
whether the theorem has a tactic-style proof, etc. Please refer to lean_dojo.data_extraction.traced_data.TracedTheorem
and lean_dojo.data_extraction.traced_data.TracedTactic for details.
Constructing Benchmark Datasets Using LeanDojo
Traced repos/files/theorems provide all information we need, and we can construct concrete machine learning datasets with some additional post-processing. See our examples of constructing datasets from Lean 3’s mathlib and Lean 4’s mathlib4.
Interacting with Lean
LeanDojo enables interacting with Lean programmatically using tactics. Please see the demos (Lean 3 version, Lean 4 version) and dojo.py.
Caching
Tracing large repos such as mathlib can take a long time (~1 hour if using 32 CPUs) and at least 32 GB memory.
Therefore, we trace the repo only once and cache the traced repo for fast access in the future.
The default cache directory is ~/.cache/lean_dojo, which can be configured through the CACHE_DIR environment variable.
Traced repos in the cache are read-only, which prevents accidental modifications.
You need chmod if you want to, e.g., clean the cache. However, refrain from manually modifying the cache while LeanDojo is running.
It may lead to unpredictable behaviors, e.g., LeanDojo may attempt to refill the cache.
Traced repos in the cache are portable across machines. We host a number of them on AWS S3,
and LeanDojo will automatically download them if they are not in the local cache. To disable this behavior and
build all repos locally, set the DISABLE_REMOTE_CACHE environment variable to any value.
The caching mechanism in LeanDojo is implemented in cache.py.
Environment Variables
LeanDojo’s behavior can be configured through the following environment variables:
CACHE_DIR: Cache directory (see Caching). Default to~/.cache/lean_dojo.DISABLE_REMOTE_CACHE: Whether to disable remote caching and build all repos locally. Not set by default.TMP_DIR: Temporary directory used by LeanDojo for storing intermediate files. Default to the systems’ global temporary directory.NUM_PROCS: Number of parallel processes for data extraction. Default to 32 or the number of CPUs (whichever is smaller).TACTIC_TIMEOUT: Maximum time (in milliseconds) before interrupting a tactic when interacting with Lean (only applicable to Lean 3). Default to 5000.TACTIC_CPU_LIMIT: Number of CPUs for executing tactics when interacting with Lean. Default to 1.TACTIC_MEMORY_LIMIT: Maximum memory when interacting with Lean. Default to 16 GB.GITHUB_ACCESS_TOKEN: GitHub personal access token for using the GitHub API. They are optional. If provided, they can increase the API rate limit.LOAD_USED_PACKAGES_ONLY: Setting it to any value will cause LeanDojo to load only the dependency files that are actually used by the target repo. Otherwise, for Lean 4, it will load all files in the dependency repos. Not set by default.VERBOSEorDEBUG: Setting either of them to any value will cause LeanDojo to print debug information. Not set by default.
LeanDojo supports python-dotenv. You can use it to manage environment variables in a .env file.
Questions and Bugs
For general questions and discussions, please use GitHub Discussions.
To report a potential bug, please open an issue. In the issue, please include your OS information, the exact steps to reproduce the error, and complete logs in debug mode (setting the environment variable
VERBOSEto 1). The more details you provide, the better we will be able to help you.